ChatGPT and DeepSeek may soon face competition from a new player—not from the United States, China, or Europe, but from Latin America. Latam-GPT, a large language model under development in Chile, is being designed with a distinct regional perspective. Developed over the past two years by the Chilean National Center for Artificial Intelligence (CENIA), Latam-GPT is being created with the support of multiple Latin American countries. The model is expected to launch by mid-2025 and has been carefully trained on validated data sources. Beyond its technical ambition, the project aspires to reshape how Latin America engages with artificial intelligence—and how AI systems perceive the region in return.
A Model for Regional Collaboration and Technological Sovereignty
Currently under construction, Latam-GPT is intended to be an open-access, free-to-use, and collaborative AI model. CENIA, a nonprofit private organization, is working alongside governments, universities, and institutions throughout Latin America to foster the development of AI technologies rooted in the region.
Álvaro Soto, director of CENIA, views the global surge in AI development as a challenge for Latin America. “Latin America has often remained on the margins of recent technological revolutions,” he explained. Soto argues that the region must actively build the capabilities to participate in the current wave. “We need to be in a position to investigate, adapt, and modify these models according to local needs,” he said.
While achieving sovereignty in AI development is one of the project’s objectives, Soto emphasized that the broader goal is to enable cooperation. “There’s a degree of sovereignty involved, yes,” he noted, “but more importantly, we aim to collaborate with partners around the world—in Europe, the U.S., wherever possible—and be active contributors, not just passive recipients, in the development of these technologies.”
A central purpose behind Latam-GPT and other initiatives promoted by CENIA—such as building machine translation tools for Indigenous Latin American languages—is to act as a “facilitator,” as Soto puts it, providing access to innovation for local companies and entrepreneurs. This would, in turn, help accelerate technological progress throughout the region.
Soto also pointed out that leading models like ChatGPT, DeepSeek, and Gemini have been primarily trained on English-language data from the Global North. “That leads to blind spots or hallucinations when users seek information specifically about Latin America,” he explained. This gap in coverage inspired the vision behind Latam-GPT: to develop a model trained on Latin American data, with a better grasp of regional context and knowledge.
Custom-Made AI, Built for and by Latin America
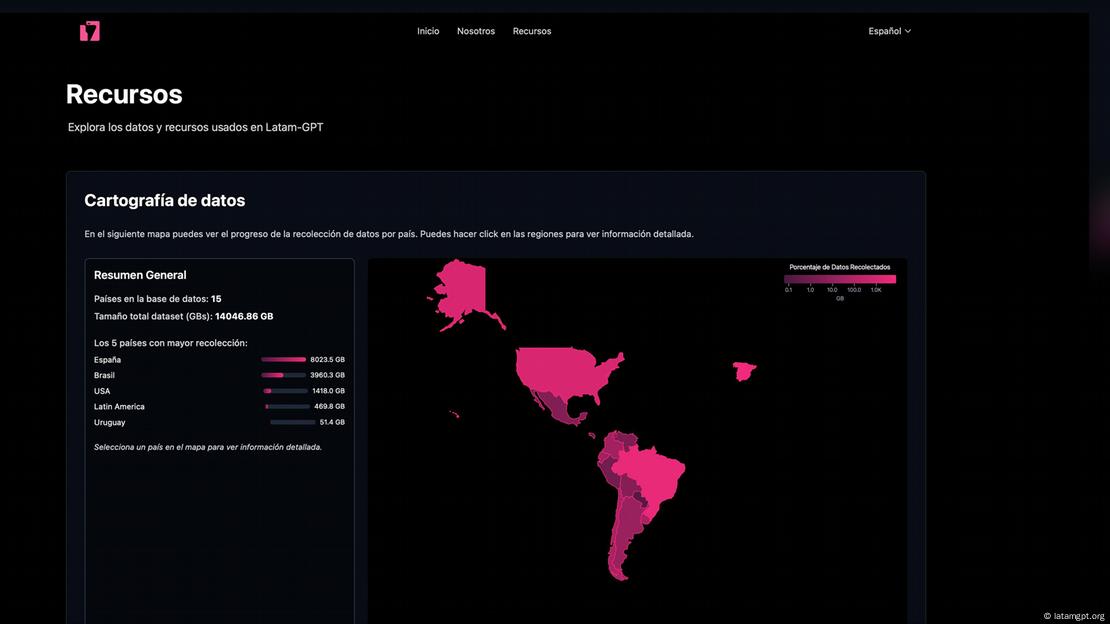
In terms of data sourcing, Latam-GPT has been developed through markedly different methods than its major international counterparts. Soto highlighted the challenges faced by smaller teams. “Big companies have vast resources. In Latin America, we don’t. So we had to take a collaborative approach,” he said. While large tech firms have relied on automated mass scraping of the web, CENIA’s strategy has involved a more deliberate and community-based model of data gathering.
This has meant “knocking on doors” across the region, according to Soto—working directly with universities, ministries, and nonprofit foundations from various Latin American countries. Through these partnerships, CENIA has obtained permission and support to use relevant data for model training. Collaboration from local developers, AI researchers, and data science professionals has been essential. Contributions from large datasets like RedPajama and involvement with the Spanish-language NLP community SomosNLP have also played an important role.
Latam-GPT represents a bottom-up development initiative, as Soto describes it, though it also benefits from top-down support. Over 30 organizations across different countries have contributed funding and resources. Key backers include the Chilean government, which has supported both financially and through advances in AI regulation, and institutions like the University of Tarapacá, which provided infrastructure powered by renewable energy.
While emphasizing the value of external support, Soto also clarified that Latam-GPT is not being built entirely from scratch. Instead, the project is based on a refined version of Meta’s open-source Llama 3 model. This distinguishes Latam-GPT as a tailored adaptation of an existing foundation model, rather than a fully original framework like DeepSeek or ChatGPT.
In its initial release, Latam-GPT will include 70 billion parameters and be trained on a dataset comprising 2 trillion tokens. It will operate fluently in Spanish, Portuguese, and English, according to Soto. He acknowledged the extended timeline of the project, noting that development has taken much longer than anticipated. The AI will first be released as a text-based chatbot, with plans to expand its capabilities over time. The public launch is scheduled for July 2025.





